
Unbroken Meaning is a project that investigates the ability of current speech-to-text algorithms to understand Caribbean Trinidad English Creole (TrinEC) and African Diaspora-derived Pidgin creole. It seeks to demonstrate the bias of these algorithms while developing new algorithms that are better suited to recognize phrases and languages of these communities. Additionally, it seeks to create suitable text-to-speech methods for proper computer pronunciation of these languages. Finally, Unbroken Meaning collects audio samples of phrases and speech patterns to serve as a method of archiving the vocabulary and grammar of selected communities. We were invited by the Library of Congress to showcase Unbroken Meaning at the Playtest conference. Playtest brought together a diverse group of thought leaders and creative technologists working at the intersection of virtual reality, emerging media, and humanities research.
Machine learning (ML) uses statistical techniques to give computer systems the ability to "learn" from data and thus improve performance on a specific task without being explicitly programmed. Though this field is growing exponentially and becoming ever more integrated with ubiquitous computing, there exists a lack of representation of diverse groups in the field. This lack of representation in the programing of ML algorithms, collection of datasets, and development of ML based products is deleterious and diminishes the potential positive social impact, efficacy, and economic impact of the field. This lack of diversity additionally has the potential to manifests itself in products and systems that are biased and dangerous to underrepresented groups by not fully taking them into account.
This project was created as part of C.T.R.L. [CULTURE, TECHNOLOGY, RESEARCH, LANGUAGE], a collaborative endeavor between Nikita Huggins, Ayodamola Tanimowo Okunseinde, and Nicole Lloyd. C.T.R.L. seeks to address bias in machine learning systems while creating tools and artworks that make machine learning environments more accessible. The collective not only produces and analyses alternate machine learning datasets, but also create related artworks that are meaningful and expressive. Some of the methodology implemented include identifying unique modes of communication internal to specific communities, analysis of language structures and syntax, the use of machine learning tools to attempt to pull meaning from text, and the creation of physically based works that promote diversity in the machine learning field. The collective aims also to teach machine learning tools and methods to underrepresented communities, develop related art & technology curricula, and to archive assets that may be utilized as research material.


 Close Project
Close Project

Corpora is the collection of datasets and algorithmic models developed by Black Corpus. The collection is available for use by artists, educators, and researchers of all kinds interested in promoting the Black Corpus agenda. Included in Corpora are ML language models generated from the individual and collective works of authors such as W.E.B. Du Bois, Octavia Butler, James Baldwin, and more.
Corpora was created as part of my S.I.R. [Something in Residence] residency at ITP. During this residency, I contributed these datasets to the ML5.js research project. The Subtext of a Black Corpus shares the narrative behind this research.
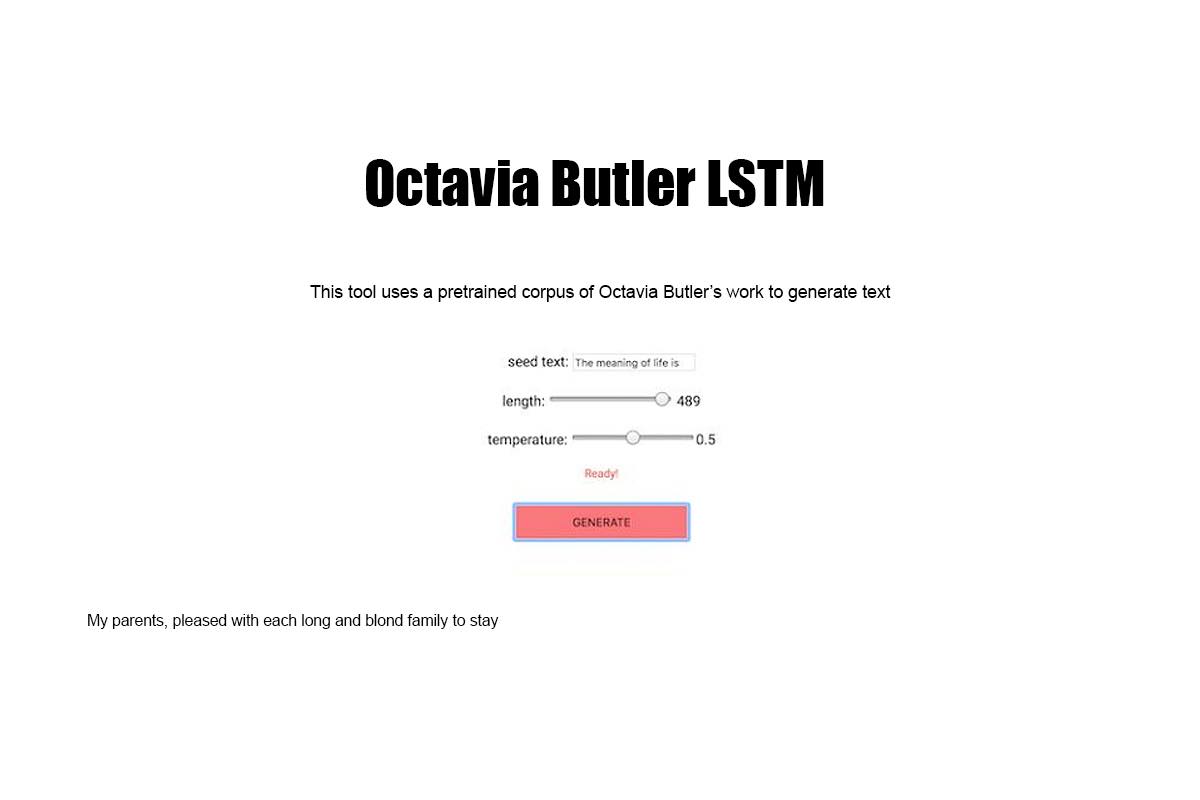
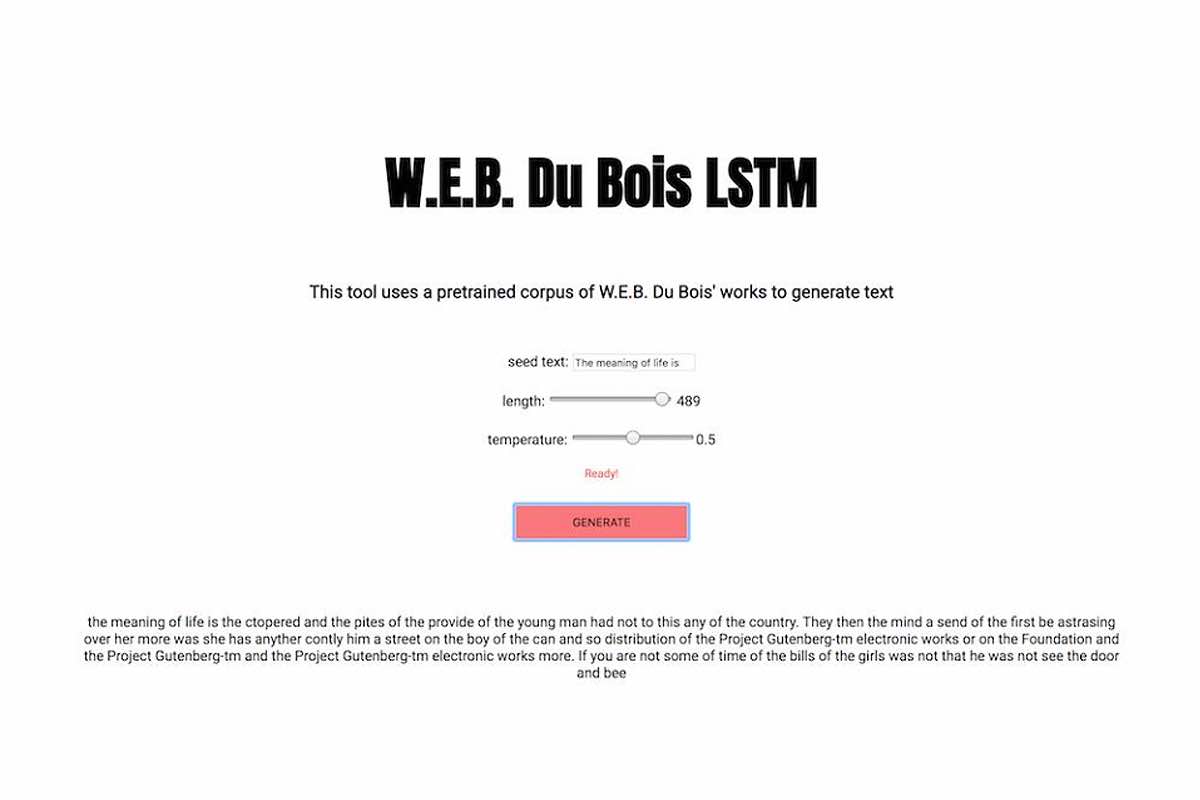 Close Project
Close Project

ML5.js aims to make machine learning approachable for a broad audience of artists, creative coders, and students. The library provides access to machine learning algorithms and models in the browser, building on top of TensorFlow.js with no other external dependencies. The library is supported by code examples, tutorials, and sample datasets with an emphasis on ethical computing. Bias in data, stereotypical harms, and responsible crowdsourcing are part of the documentation around data collection and usage.
ML5.js is a Google-backed research project created at NYU's Interactive Telecommmunications Program (ITP). During the course of development, we invited artists in the machine learning landscape to come to ITP to share their knowledge with us.
I coordinated artist visits, artist talks and workshops.
I also created the ITP artificial intelligence blog to showcase the work that students are doing in the field.
Close ProjectTrini Talk is an online platform designed to communicate and preserve the Trinidad English Creole Language. Using an interactive web platform, Trini Talk teaches the oral language of Trinidad through the island’s history, shows how the language is used and establishes a platform to preserve the language.
View my design process